DTS는 은행, 카드사, 증권, 보험, 캐피탈, 핀테크 등 민감한 금융 데이터를 보유한 기관을 위한 엔터프라이즈급 보안 합성데이터 생성·변환 솔루션입니다.
원본 데이터 비접근(Zero-Access) 아키텍처와 차등정보보호(Differential Privacy) 기술을 결합해, 개인정보보호법, 신용정보법, GDPR 등 금융권 규제와 내부 컴플라이언스 요구를 충족하면서도 외부 협업, 모델 개발, 데이터 상품화를 안전하게 지원합니다.
거래 로그, 카드 사용 내역, 대출·심사 정보 같은 정형 데이터뿐 아니라 상담 녹취·민원 텍스트, 콜로그, 앱 이벤트, 시계열 FDS 로그까지 멀티모달 데이터를 합성데이터로 자동 변환하여, 실데이터 반출 없이도 신용평가, FDS, AML, CRM, 리스크 모델링 등 핵심 과제에 바로 활용할 수 있습니다.
DTS를 통해 금융기관은 복잡한 가명·익명 처리 절차 없이 비식별화와 합성 생성을 한 번에 수행하며, 규제와 보안 이슈로 묶여 있던 고위험 데이터를 재식별 위험 없이 고성능 AI 학습 데이터로 전환할 수 있습니다.

제품 상세
Key Point

주요 특징
1. 원본을 외부로 내보내지 않는 안전한 합성데이터 엔진
기업·기관이 보유한 고객정보, 거래내역, 로그·센서 데이터에는 민감정보가 섞여 있어 직접 반출·공유하기 어렵습니다.
DTS는 원본 데이터를 외부 서버로 이동시키지 않고, 비접근(Non-Access) 구조와 프라이버시 보호 기술을 결합해 합성데이터를 생성합니다. 이 방식은 모델 공격이나 내부 유출 상황에서도 원본이 그대로 남아 있어, 보안과 컴플라이언스 요구를 동시에 만족합니다.
2. 단순 비식별이 아닌, 분석과 AI에 바로 쓰이는 고성능 데이터
기존 비식별·마스킹 방식은 개인정보는 가릴 수 있지만, 결측·편향·희소 클래스 때문에 실제 분석과 AI 학습에 활용하기 어렵다는 한계가 있습니다.
DTS는 합성 과정에서 결측값 보정, 희소 이벤트 증강, 편향 완화, 필요한 속성 추가 등을 함께 수행해, 원본보다 더 균형 잡힌 고성능 데이터셋을 만들어 줍니다. 실험·시뮬레이션, 모델 개발, 서비스 고도화까지 하나의 데이터로 이어갈 수 있습니다.
3. 보안·품질 검토를 자동화해 데이터 활용 속도 향상
새로운 데이터를 외부와 공유하거나 다른 팀과 활용하려면, 보안·법무·데이터팀의 검토가 길게는 수개월 걸리기도 합니다.
DTS는 통계적 유사도, 머신러닝 성능, 재식별 위험도 등 주요 지표를 산출하는 리포트를 제공해, 데이터 품질과 프라이버시 수준을 정량적으로 확인할 수 있게 합니다. 그 결과, 별도 전문 인력 없이도 빠르게 “사용 가능 여부”를 판단하고 프로젝트를 바로 시작할 수 있습니다.
4. 표·텍스트·이미지·시계열을 하나의 플랫폼에서 처리
현재 기업과 기관의 데이터는 CRM 테이블, 콜센터 텍스트, 의료·산업 이미지, 센서·로그 시계열 등 다양한 형태가 뒤섞여 있습니다.
DTS는 하나의 프레임워크 위에서 표·텍스트·이미지·시계열 등 멀티모달 데이터를 모두 지원해, 도메인마다 다른 툴을 도입하지 않아도 됩니다. 데이터 유형이 늘어나도 동일한 엔진과 UI로 관리·확장할 수 있어, 운영 복잡도와 비용을 크게 줄여줍니다.
5. 반출 제한 환경에서도 협업과 PoC를 가능하게 하는 데이터
클라우드 보안 정책, 망분리, 내부 규정 때문에 원본 데이터를 파트너사·연구기관·해외 법인과 공유하기 어려운 경우가 많습니다.
DTS로 생성한 합성데이터는 원본과 동등한 분석 가치와 패턴을 유지하면서도 개인·기밀 정보를 포함하지 않기 때문에, 반출이 어려운 환경에서도 외부 협업·PoC·벤더 평가·모델 벤치마킹 등에 안심하고 활용할 수 있는 “공유 가능한 데이터 자산”이 됩니다.
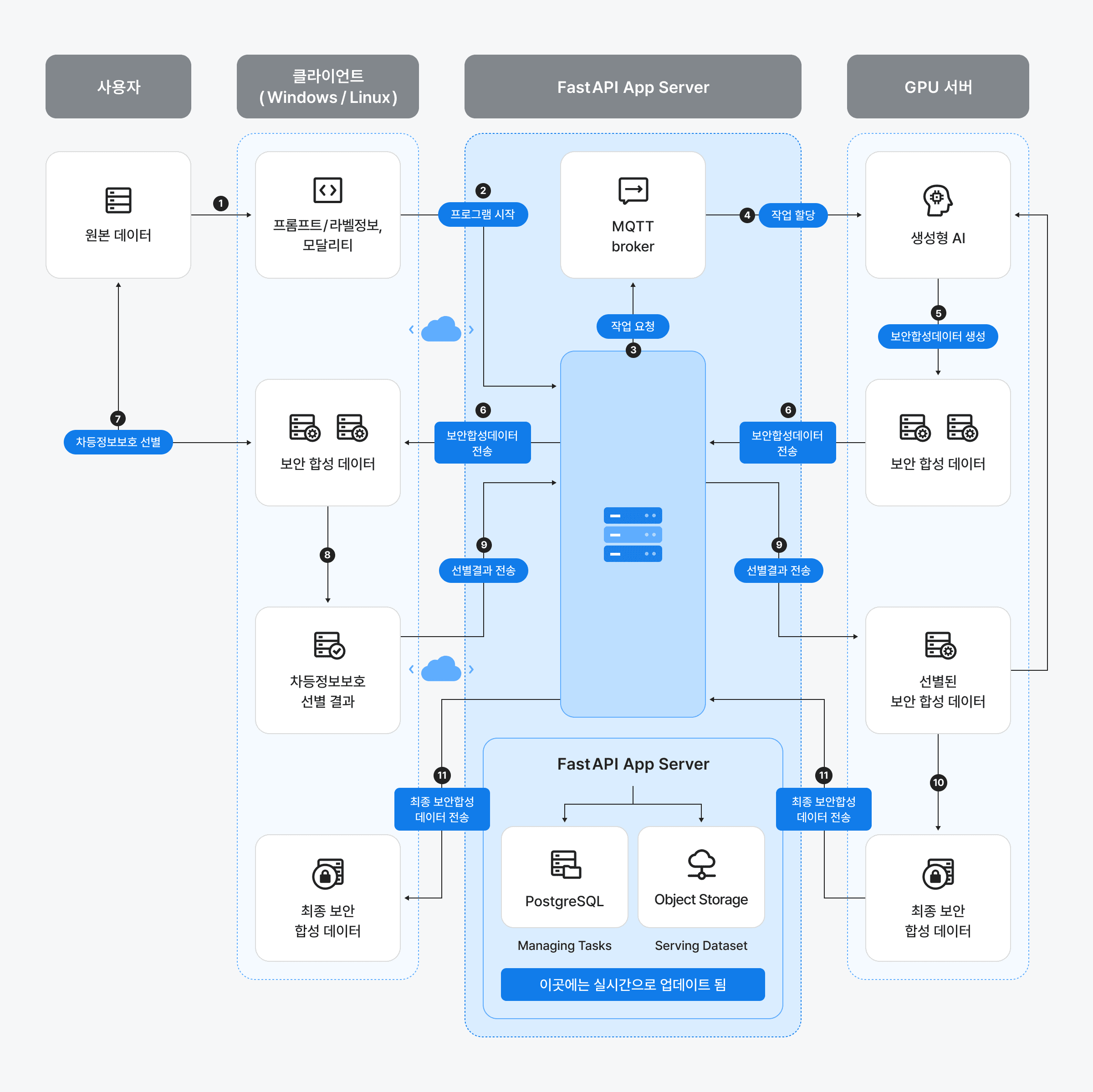
아키텍처
요금
요금
(VAT 별도)
| 구분 | 가격 | 생성 데이터 수 |
|---|---|---|
| 이미지 (512 x 512픽셀 기준) | 20,000,000 | 5,000 |
| 표 (50컬럼 x 1행 기준) | 15,000,000 | 5,000 |
| 텍스트 (A4 1장 기준) | 15,000,000 | 5,000 |
•Time series, DNA 등 특수 도메인에 대한 단건 생성은 추가 비용이 발생할 수 있습니다.
•표 데이터 중 일부 컬럼만 변경이 필요한 경우, 커스텀 비용이 책정될 수 있습니다.
•기본가는 최고 보안 등급 기준이며, 보안 수준을 유지한 채 데이터 유용성을 높일 시 추가 비용이 발생합니다.
•원본 데이터 양이 적을수록 할증 비용이 발생할 수 있습니다.
o 1000건 미만 : 기준 금액 X 1.5
o 100건 미만 : 기준 금액 X 3
o 10건 미만 : 기준 금액 X 5
•On-Premise 구축 시 추가 비용 및 기간이 발생할 수 있습니다.
•생성 및 평가 모델 엔진 포함 시 추가 비용 및 기간이 발생할 수 있습니다.
기술 지원
상품 및 기술지원 문의
Tel : 02-582-1113 / 평일: 09:00 - 12:00, 13:00 - 18:00
Email: contact@cubig.ai
Website: https://cubig.ai
활용 사례
Use cases
1. 카드·결제 사기(Fraud) 등 이상거래 탐지 (FDS) 고도화
카드 승인·취소·매입 내역, 계좌 이체 로그, 디바이스·채널 정보, FDS 룰 로그
•실제 고객 패턴과 유사한 거래 분포를 유지하면서, 사기 거래를 증강한 합성 트랜잭션 데이터셋 생성
•희소한 Fraud 케이스를 보완해 딥러닝 기반 FDS, 실시간 이상거래 탐지 모델 성능을 높이고, 새로운 사기 시나리오를 사전 학습
•제3의 분석사·솔루션 벤더와 합성데이터 기준으로 모델 벤치마킹·PoC를 수행해, 실데이터 반출 없이도 협업 가능
2. 신용평가·대출 심사·리스크 모델링
대출 신청 정보, 상환 이력, 소득·직장·재무 데이터, 부도·연체 이력, 내부 리스크 점수
•실제 포트폴리오와 동일한 분포를 갖는 가상의 차주 데이터를 생성해, 개인신용정보를 노출하지 않고도 신규 CSS, PD·LGD 모델을 개발·튜닝
•경기 침체, 금리 급등 등 다양한 시나리오를 합성데이터로 시뮬레이션하여 포트폴리오 리스크를 정량 분석
•리스크·여신 부서와 데이터·모델 부서, 외부 컨설팅사가 합성데이터를 기준으로 리스크 전략·심사 정책을 공동 설계
3. 마이데이터·오픈뱅킹·디지털 채널 분석
마이데이터 통합 이용 이력, 오픈뱅킹 계좌·거래 정보, 앱·웹 행동 로그, 추천·알림 반응 데이터
•고객을 유추할 수 없는 합성 마이데이터 프로필을 생성해, 교차 판매·자산관리·소비 패턴 분석에 활용
•디지털 채널에서의 클릭, 조회, 이탈 패턴을 그대로 반영한 합성 행동 데이터를 기반으로 추천·퍼널 분석·개인화 모델 고도화
•제휴 금융사·핀테크와 합성데이터를 교환해, 실제 계좌·거래를 노출하지 않고도 조인트 상품·서비스를 설계
4. 콜센터·민원·VOC 기반 CX 인사이트 및 LLM 활용
콜센터 상담 이력, 고객 불만·칭찬 VOC, 채팅 상담 로그, 설문 응답, NPS 데이터
•이름·연락처 등 식별 정보는 제거하고, 불만 유형·감정·이슈 키워드는 그대로 반영한 합성 텍스트 데이터 생성
•합성 VOC 데이터를 기반으로 이탈 징후 예측, 불만 유형 자동 분류, 상담 스크립트 추천 모델을 학습
•LLM 기반 상담 어시스턴트/챗봇 학습에 필요한 고품질 대화 데이터를, 실 고객 대화 노출 없이 확보
5. 데이터 상품화·제휴·내부 데이터 레이크 구축
통신·카드 결제 패턴, 상점별 매출 데이터, 위치·가맹점 정보, 제휴사 캠페인 반응 데이터
•민감한 속성은 제거·합성하고, 상권·소비 패턴·업종별 매출 구조는 유지한 합성 소비 데이터를 만들어 데이터 상품·인덱스 형태로 판매
•통신사·커머스·모빌리티 등 타 산업과 합성데이터 기반 제휴를 통해, 오프라인·온라인 결합 타겟팅, 상권 분석, 공동 마케팅 모델 개발
•계열사·조직별로 흩어진 데이터를 합성데이터 레벨에서 통합해 전사 공통 금융 데이터 레이크를 구성, 분석·AI 팀이 안전하게 공유·재활용